Easily analyse audio features from Spotify playlists — Part 2.
A simple guide to getting audio features and preview audio files from Spotify playlists, using Python.

Welcome back! In Part 1 I showed you how to get audio features, metadata, and preview MP3s from Spotify playlists, using GSA. In Part 2 we will see how we can use GSA as part of a larger data collection. Go to Part 3 if you want to try some statistics and visualisation.
Prerequisites
This shows you how to get GSA up and running
- example_data.csv
The file experimentData.csv can be found in the GSA repository. If you followed Part 1, this should be in your folder where you extracted the GSA zip file.
Our experiment
We will imagine a mock experiment, where we have asked three participants to submit some playlists each, along with a rating of each playlist. We have asked the participants to post links to their playlists using the “Copy Playlist Link” option. In addition, we have made sure that the participants have made their playlists public.

We will get audio features, metadata, and preview audio files for each of these playlists. To facilitate a quicker data gathering process we will also use Python’s joblib to parallelize our processing, and use tqdm to make nice progress bars.
This information is collected in a comma-separated values file (.csv), with three columns: playlistURI, participant, and rating (example_data.csv). Out of these, only playlistURI is required. You can add any other column you want, just make sure that it is read properly by Pandas.
Getting started
We first need to import the libraries we are going to use:
import pandas as pd
import os.path
import GSA
from joblib import Parallel, delayed
from tqdm import tqdmpandas handles reading and formatting data.
os.path allows us to easier write to our filesystem.
GSA is the Generalized Spotify Analyser.
joblib handles parallel processing.
tqdm creates progress bars.
We then need to authenticate with the Spotify API:
GSA.authenticate()Note, that in Spyder 4 there is a quirk with this process. If you paste the redirect URL into the console using control+V (on Windows), it may not work. Instead, right click with your mouse and select paste.
Reading data
We need to read our participants data into Python. For that we use Pandas, a library for data analysis and manipulation.
dataset = pd.read_csv(‘example_data.csv’, low_memory=False, encoding=’UTF-8', na_values=’’, index_col=False)From the extra arguments here, two are important. na_values=’’ sets any missing data to be not-a-number (nan). In our example dataset there is one such instance of missing data. In addition, there is no index column in our csv-file. We need to tell Pandas this by using index_col=False.
If you use Spyder you can inspect the data in the variable explorer:
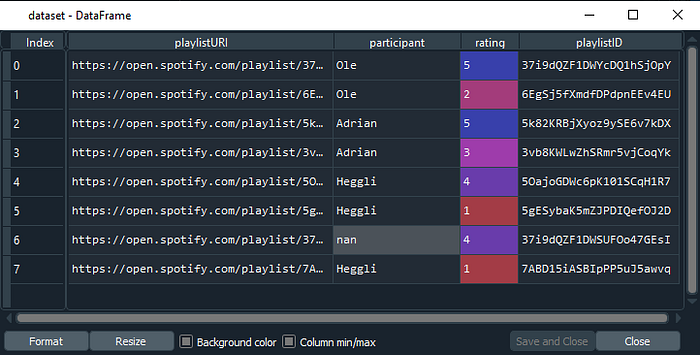
Next, we will get the playlistURI as a list. In addition, we will strip it so that it only contains the playlist ID (and not the entire url).
While GSA.getInformation will work with the complete url, this will cause issues later when saving files as these contain unallowed characters, making us unable to save files.
loc_start = URIlist[0].find(‘/playlist/’)# Strip down to only the actual ID with length 22
IDlist = [playlist[loc_start+10:loc_start+10+22] for playlist in URIlist]# Add the ID back to the original dataset for later lookup
dataset[‘playlistID’] = IDlist
Getting audio features and metadata
We are now ready to download the audio features and metadata! To speed up the process we’ll parallelize it. In addition, we will make a progress bar so we can see how things are coming along.
listsId = tqdm(IDlist, desc=’Getting audio features’)results = Parallel(n_jobs=8, require='sharedmem')(delayed(GSA.getInformation)(thisList) for thisList in listsId)
Here, we first make a tqdm object IDlist_tqdm out of IDlist, which is the list containing all the playlist IDs we are checking out. We then use the Parallel function to run GSA.getInformation on each list in IDlist_tqdm.
Here, n_jobs is the number of threads you want to run in parallel. Getting information is not an intensive task, so feel free to set it to the maximum amount of threads in your system.
Note, Spotipy (the API-wrapper we’re using) should automatically refresh your access token. If you run into errors, try deleting the .chache-* file and running GSA.authenticate() again.
The GSA.getInformation function is created so that if your data gathering process fails, times out, or you need to interrupt it for some reason, you can just start it again. It will not re-download already downloaded data.
Adding participant information back to the dataframe
We have now downloaded all the audio features and metadata. Now, we need to add this together with the participant information.
First, we need to read in all the pickle files created by GSA.getInformation.
output=[]for thisList in results:
if thisList == 'error':
print('Found a playlist not downloaded.')
else:
thisFrame = pd.read_pickle(thisList)
output.append(thisFrame)# flatten
output = pd.concat(output)
In the case that GSA encounters a track without audio features or metadata, this track will be labelled “EMPTYDATAFRAME”. Let’s filter those out:
empties = output[output[‘TrackName’] == ‘EMPTYDATAFRAME’]output.drop(empties.index, inplace=True)
Now we merge this dataframe with the original dataset:
merged_output = dataset.merge(output, on =’playlistID’, how=’left’)This now contains a dataset wherein each row is a track, with associated information. In Part 3 we will look at how to analyse and visualize this.
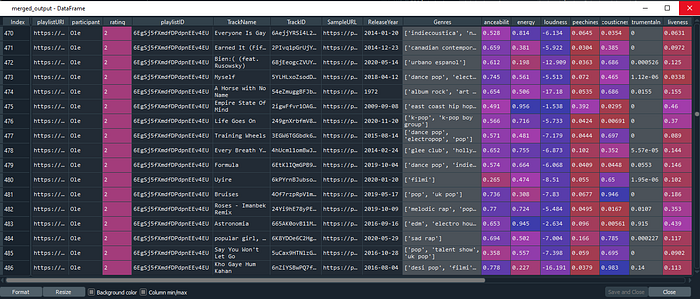
Downloading preview MP3s
To download preview MP3s we will follow a similar process. First we need to get the information required by GSA.downloadTracks out from out dataset:
to_download = merged_output[[‘SampleURL’, ‘TrackName’, ‘TrackID’, ‘playlistID’]].values.tolist()We then turn this into a tqdm object to get a nice progress bar, and start downloading tracks in parallel:
to_download = tqdm(to_download, desc=’Downloading tracks’)downloaded = Parallel(n_jobs=8)(delayed(GSA.downloadTracks)(track=thisTrack) for thisTrack in to_download)
This function is also designed to cope with time outs, dropped internet, or accidental coffee spills. If a track is already downloaded, it will not download it again, so you can halt this process any time you want.
As we saw in Part 1, not all tracks have a preview. To get a dataset with only the tracks we downloaded we will turn the output from GSA.downloadTracks into a dictionary:
downloaded_df = pd.DataFrame(downloaded, columns=[‘TrackID’, ‘Downloaded’])downloadedKey = dict(zip(downloaded_df.TrackID, downloaded_df.Downloaded))
We then add this back to our merged_output dataframe, by creating a new column called “Downloaded” which we will set to 1 if successfully downloaded:
merged_output[‘Downloaded’] = 0merged_output[‘Downloaded’] = merged_output[‘TrackID’].map(downloadedKey)
The last step is to save a version of the dataset containing only those tracks we have downloaded.
merged_output_downloaded = merged_output[merged_output[‘Downloaded’] == 1]merged_output_downloaded.to_csv(‘Data/dataset_with_audiofeatures_downloaded.csv’, encoding=’UTF-8')
Summary
You have now learned how to use GSA to work as part of a larger data collection. In this mock experiment we had three participants submit playlists, then we downloaded audio features, metadata, and preview MP3s from the tracks in the playlists.
The example script (GSA_example.py) handles experiment datasets with any number of columns, so you could have your participants rate playlists on multiple dimensions, or you could compare the most popular playlists per country, per season, or any other comparison that seems interesting.
The output of this tutorial is a dataset which you can analyse and visualise, and I’ll show you how in Part 3.
